VeRA: Vector-based Random Matrix Adaptation
Dawid J. Kopiczko, Tijmen Blankevoort, Yuki M. Asano
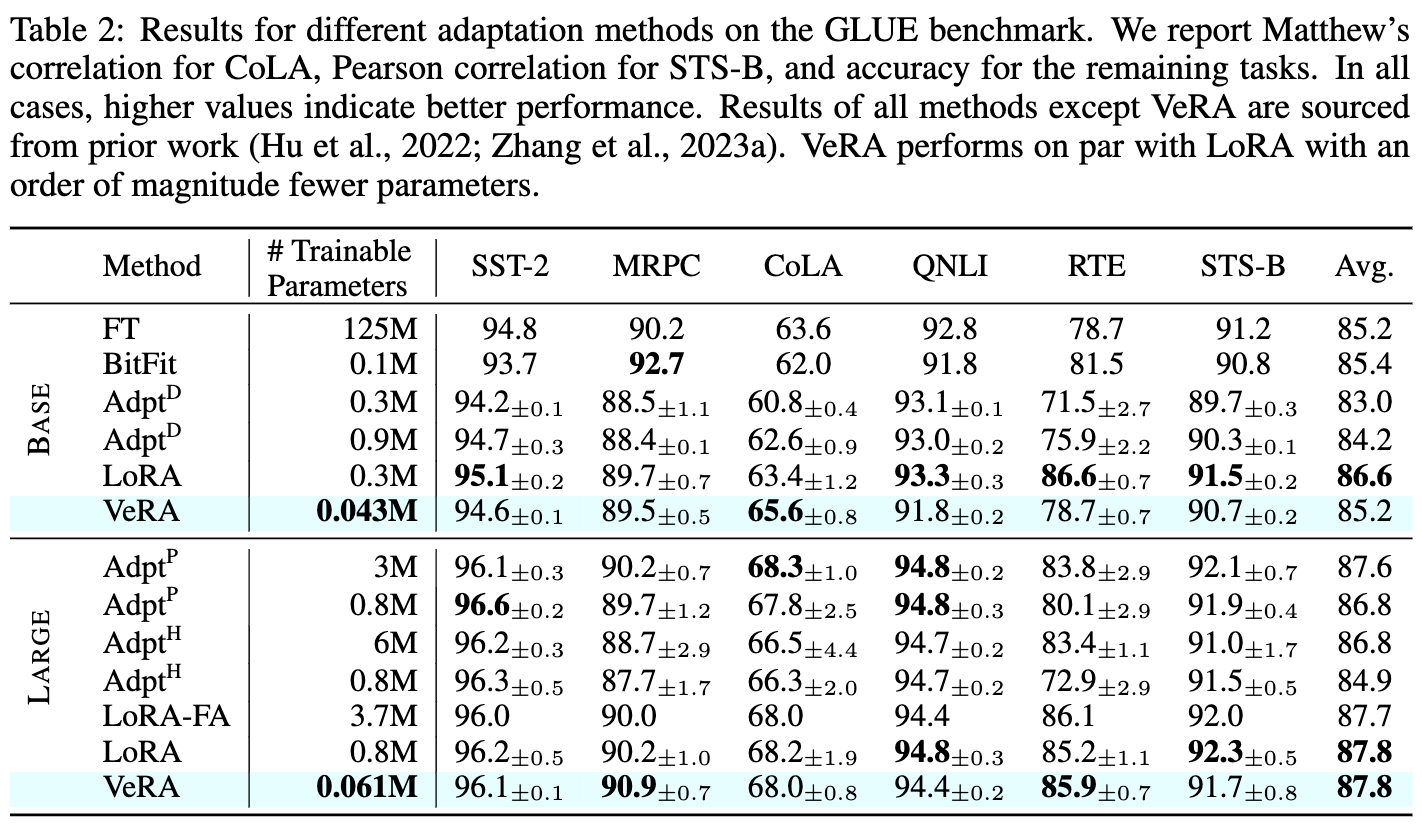
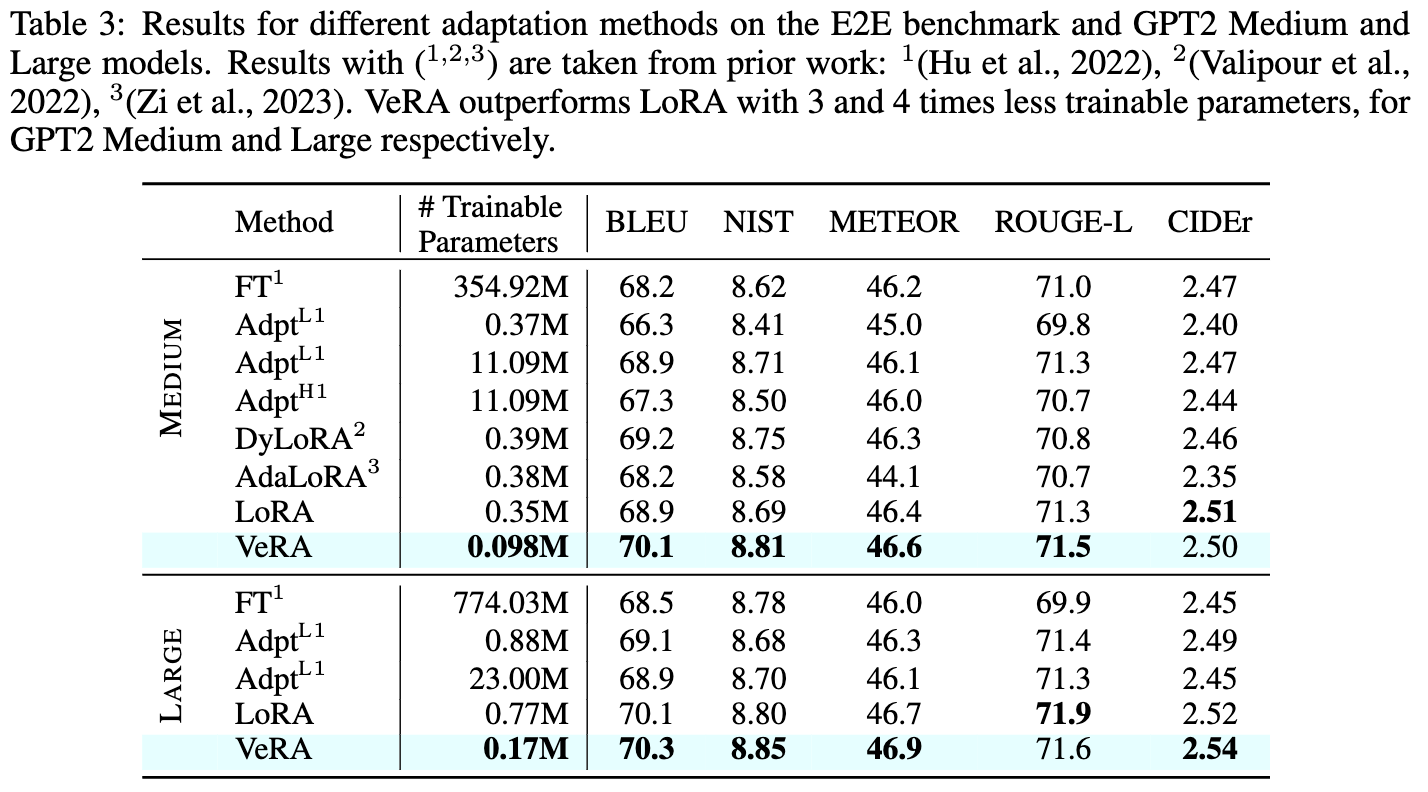
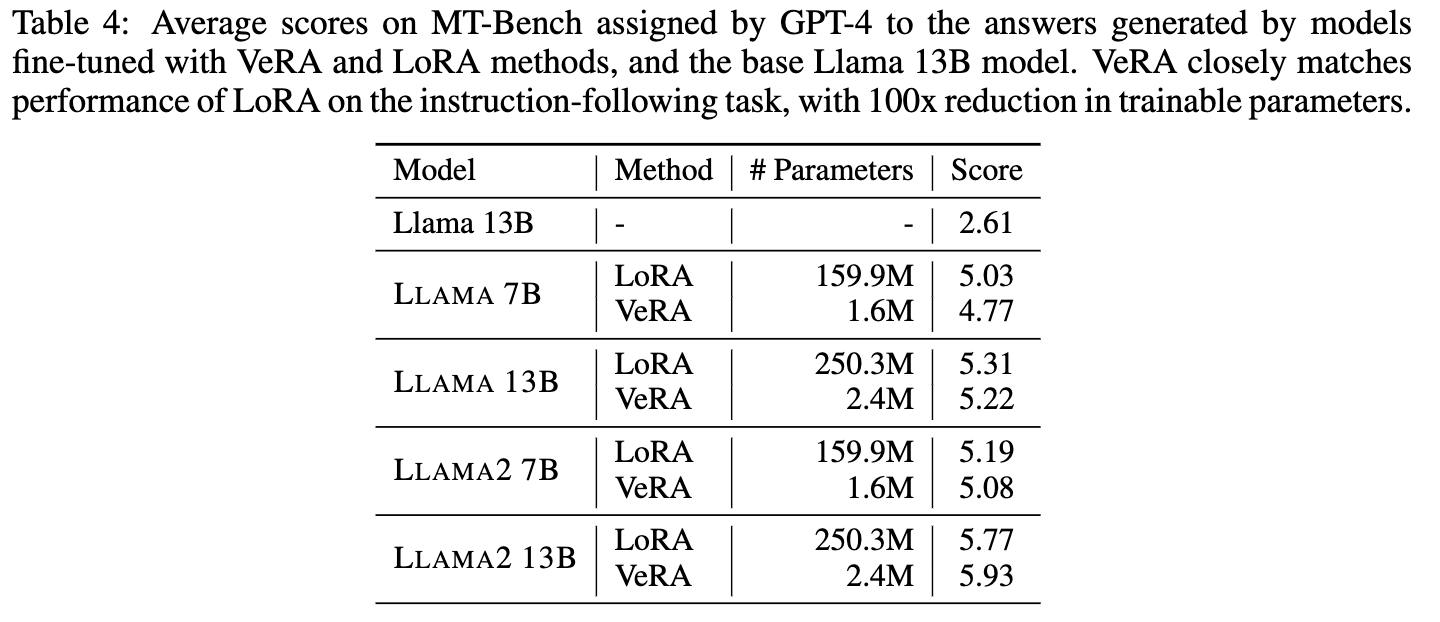
Low-rank adapation (LoRA) is a popular method that reduces the number of trainable parameters when finetuning large language models, but still faces acute storage challenges when scaling to even larger models or deploying numerous per-user or per-task adapted models. In this work, we present Vector-based Random Matrix Adaptation (VeRA), which significantly reduces the number of trainable parameters compared to LoRA, yet maintains the same performance. It achieves this by using a single pair of low-rank matrices shared across all layers and learning small scaling vectors instead. We demonstrate its effectiveness on the GLUE and E2E benchmarks, image classification tasks, and show its application in instruction-tuning of 7B and 13B language models.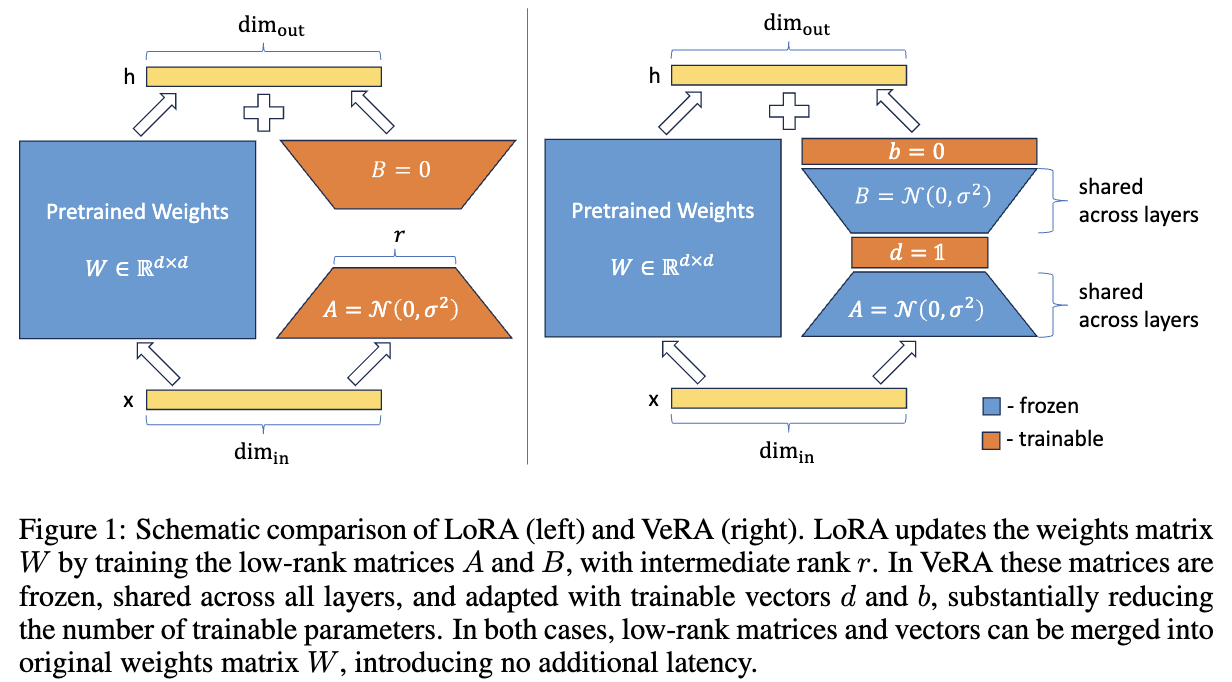
Bibtex
@inproceedings{kopiczko2024vera,title={VeRA: Vector-based Random Matrix Adaptation},
author={Dawid J. Kopiczko and Tijmen Blankevoort and Yuki M. Asano},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=NjNfLdxr3A}
}